Data and machine learning in financial fraud prevention

In the 2018 Global Economic Crime and Fraud Survey, PWC writes, “When it comes to fraud, technology is a double-edged sword. It is both a potential threat and a potential protector.” Huge advancements have been made in the payment space with shifts towards digital account opening, allowing people to apply for accounts strictly online. As shown below, digital account opening has become so ubiquitous, it is now an expectation.
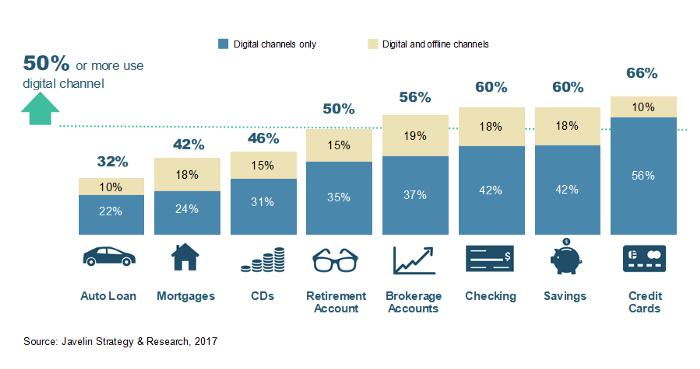
The many benefits of digital account opening, such as increased access to various financial products, come with new risks. Fraudsters can attempt to open accounts under false pretenses with the potential of instantaneous feedback loops. Through the use of technologies and machine learning, financial companies can prevent fraudsters from successful digital account openings.
At Alloy, we provide financial companies a plethora of data sources and best practices to aid them in creating rulesets for digital account opening reviews. Based on their risk adversity, they have to make the difficult decision between converting more applicants into customers while taking bigger identity risks, or enduring high back office costs in manually reviewing large numbers of applicants (and losing applicants in the process). Financial companies can leverage fraud data and machine learning to maximize the number of good application approvals while minimizing the number of manual reviews, the number of fraud application approvals, and the number of good application denials. When working to optimize rulesets, it is helpful to focus on key guiding mandates : 1) understand training data, 2) ensure interpretability, and 3) be skeptical.
Understand training data
When presenting machine learning findings, people tend to focus on the model output and associated metrics. It’s no secret, however, that in machine learning, fitting data to a model is only a portion of the process. The majority of the machine learning process is commonly devoted to data cleaning and exploratory data analysis (EDA). This stage is essential to prepare data for modeling and to better understand the data being input to the model. A model can only be as good as the data provided, so as tempting as it can be, it is essential not to take shortcuts at this step.
Instead, take time to intimately understand each feature and the necessary cleaning steps. This is the time to think about handling null values, duplicates, and any categorical variables that need to be converted to dummy variables. This is also the time to understand and visualize summary statistics surrounding your data. Should a feature’s null values be filled with the median, or would there be a better way to fill null values? The most effective way to make these decisions is to understand the feature distribution and statistics like the median and other percentiles.
Ensure interpretability
Complexity does not ensure quality. Sometimes, the simpler, the better. You don’t necessarily need deep learning to optimize rulesets. Simpler models like gradient boosted classification trees and random forests may be better. When simpler models are used, the outputs can be easily integrated into existing rulesets and can be easily understood by regulators and auditors.
Be skeptical
When a machine learning model provides promising metrics, it is tempting to immediately (and excitedly) share the results. However, it is essential to first understand the results and how they apply to the data at hand. With fraud, the number of good accounts tend to significantly outweigh the number of fraud accounts. In these instances, there may be class imbalance issues. To understand class imbalance, imagine there is a dataset in which 99% of the applications are good and 1% are fraud. A machine learning model could predict that all accounts are good and it would be 99% accurate. Despite its promising accuracy rate, the model would fail to capture any fraud. Given this, it’s important to be skeptical and question the results at hand.
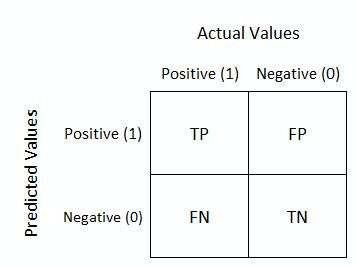
Various tools, such as downsampling the majority class or synthetic minority oversampling (SMOTE), can be invaluable in addressing class imbalance. In the case of a data set with 99% good applicants and 1% fraud, downsampling can be used to decrease the number of good applicants in the training set, or SMOTE can be utilized to increase the number of fraud applicants in the training set. Additionally, the use of metrics beyond accuracy is essential. It is often helpful to create a confusion matrix, as seen below, to understand the false positive rate (in the instance of fraud, these are good accounts misclassified as fraud) and the false negative rate (in the instance of fraud, these are fraud accounts misclassified as good accounts).
Putting it into action
While machine learning offers many benefits to optimizing rulesets, there are various challenges to generate sufficient data. Labels may not be reliable, there may be an insufficient sample size, or there may be difficulty gathering data as a result of a new stack for digital account opening. Alloy can help overcome these challenges by providing best practices and by working with clients to provide data and services that optimally fit their needs.

Kayla Hartman is a Data Scientist, helping to drive product use success through data insight and analysis. In her free time, Kayla enjoys cooking, hiking, and practically anything else outdoors.



